
以下是個人的理解,如果有錯歡迎提出~
之前接觸到了 Windows programming,常常被編碼的問題所困擾,所以做了這篇筆記~
💡 前情提要
編碼與 Bytes
1 byte = 8 bits,而每個 bit 可以表示 0 或 1,所以 1 byte 有 256 種組合 (2^8)。
電腦只讀的懂 0 和 1,但為了方便我們通常會將 1 byte 用兩個 16 進位的數字表示。
查看編碼
可以利用這個網站去查詢編碼,可以更快速的了解各編碼的差異
💡 編碼介紹
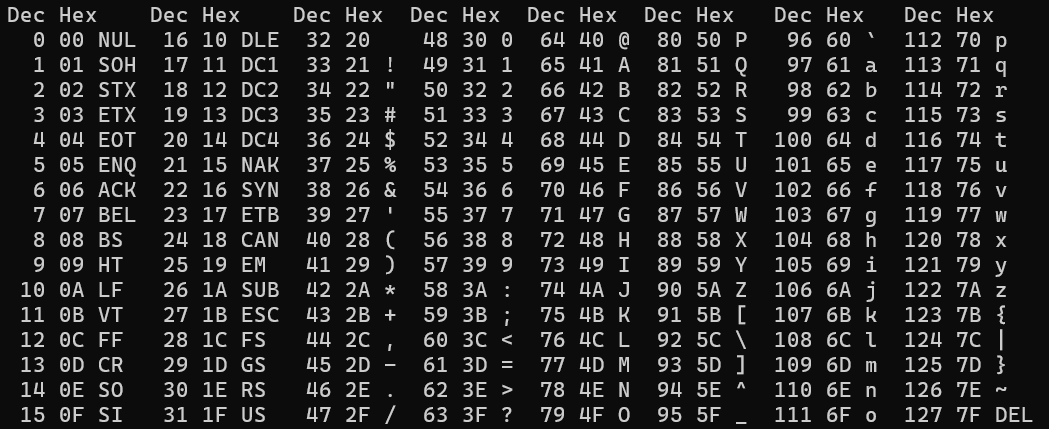
ASCII
最古老的編碼方式,包含了英文大小寫、標點符號、控制字元(換行)
- 每個字占 1 byte
- 只包含基本的英文大小寫、標點符號、控制字元 (ex: 換行)
- 從 ASCII table 就可以看到各字元的編碼,像是 A 是 41
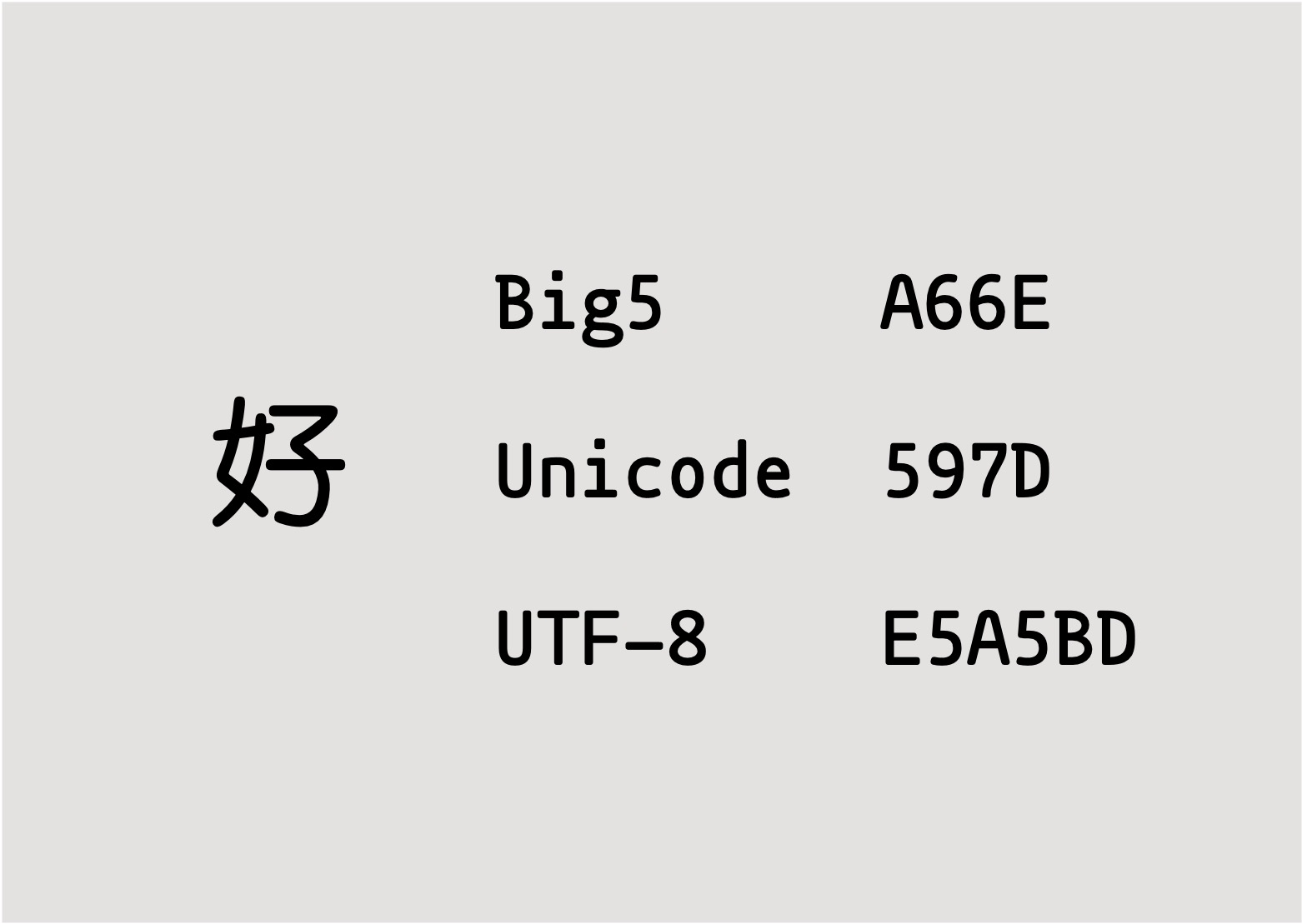
Big5
1 byte 最多只有 256 種組合,對於中文字根本就不夠用,況且世界上有那麼多的國家啊~所以各個國家都有自己的編碼原則,而繁體中文的編碼即為 Big5
- 繁體中文自己的編碼(每種語言會有自己的編碼)
- 繁體中文每個字占 2 bytes
Unicode
為了解決各語言有自己的編碼問題,使用 Unicode 即可以將所有語言的字元給定一個編號
- Unicode 本身是字元集,為每個字元提供唯一的編號,而實現該編號的方法有 UTF-8, UTF-16 等等
- 像是中文的
好所分配到的編號是597D
UTF-8
用來實現 Unicode 編號,但有些編碼其實用不到那麼多位元,所以 UTF-8 會基於 Unicode 的編號調整 byte 數量,像是一般的英文字就只需要 1 byte,而中文則花了 3 bytes 來編碼
- 1~4 bytes 滾動式調整
- 目前最常見的編碼方式
- UTF-8 編碼可還原成 Unicode 的編號
- 像是 UTF-8
E5A5BD可還原成 Unicode 的597D - 因為 UTF-8 包含了 Unicode 的所有字元,所以使用 UTF-8 編碼可以有效避免在不同語言系統間交換檔案時產生的亂碼問題




